当我们检索数据的时候,有时候需要按照某种顺序进行结果的返回,比如我们想要查询所有的英雄,按照最大生命从高到底的顺序进行排列,就需要使用ORDER BY子句。
使用ORDER BY子句有以下几个点需要掌握:
- 排序的列名:ORDER BY后面可以有一个或多个列名,如果是多个列名进行排序,会按照后面第一个列先进行排序,当第一列的值相同的时候,再按照第二列进行排序,以此类推。
- 排序的顺序:ORDER BY后面可以注明排序规则,ASC代表递增排序,DESC代表递减排序。如果没有注明排序规则,默认情况下是按照ASC递增排序。我们很容易理解ORDER BY对数值类型字段的排序规则,但如果排序字段类型为文本数据,就需要参考数据库的设置方式了,这样才能判断A是在B之前,还是在B之后。比如使用MySQL在创建字段的时候设置为BINARY属性,就代表区分大小写。
- 非选择列排序:ORDER BY可以使用非选择列进行排序,所以即使在SELECT后面没有这个列名,你同样可以放到ORDER BY后面进行排序。
- ORDER BY的位置:ORDER BY通常位于SELECT语句的最后一条子句,否则会报错。
ORDER BY 子句可以将查询的结果按照某种规则进行排序。排序方式分为升序和降序;可以基于单列或表达式排序,也可以基于多列或多个表达式排序。中文排序需要字符集和排序规则的支持,不同数据库的实现各不相同。另外,还需要注意空值的排序问题。
SQL 单列排序
按照单个字段或者表达式的值进行排序称为单列排序。单列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 [ASC | DESC];
其中,ORDER BY 用于指定排序的字段;ASC 表示升序排序(Ascending),DESC 表示降序排序(Descending),默认值为升序排序。以下是排序操作的示意图:

以下示例查询研发部门(dept_id = 4)的员工信息,并且按照月薪从高到低排序显示:
SELECT emp_name, salary, hire_date
FROM employee
WHERE dept_id = 4
ORDER BY salary DESC;
该查询中使用了 WHERE 过滤条件,此时 ORDER BY 子句位于 WHERE 之后。该语句执行的结果如下:

对于升序排序,数字按照从小到大的顺序排列,字符按照编码的顺序排列,日期时间按照从早到晚的顺序排列;降序排序正好相反。
在上面的查询结果中,“张苞”和“廖化”的月薪都是 6500。那么他们俩谁排在前面,谁排在后面呢?答案是不确定。如果要解决这个问题,需要使用多列排序。
SQL 多列排序
多列排序是指基于多个字段或表达式的排序,使用逗号进行分隔。多列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 ASC, col2 DESC, ...;
首先基于第一个字段进行排序;对于第一个字段排序相同的数据,再基于第二个字段进行排序;依此类推。
以下语句查询研发部门(dept_id = 4)的员工信息,并且按照月薪从高到低排序,月薪相同时再按照入职先后进行排序:
SELECT emp_name, salary, hire_date
FROM employee
WHERE dept_id = 4
ORDER BY salary DESC, hire_date;
该查询的结果如下:

“廖化”排在了“张苞”之前,因为他的入职日期更早。
在指定排序字段时,除了使用字段名或者表达式之外,也可以使用这些字段在 SELECT 列表中出现的顺序表示。上面的示例可以改写如下:
SELECT emp_name, salary, hire_date
FROM employee
WHERE dept_id = 4
ORDER BY 2 DESC, 3;
在 SELECT 列表中,salary 是第 2 个字段,hire_date 是第 3 个字段。因此该语句也是先按照月薪从高到低排序,月薪相同时再按照入职先后进行排序。
接下来我们讨论一类特殊的排序问题:中文排序。
SQL 中文排序
在创建数据库或者表时,我们会指定一个字符集(Charset)和排序规则(Collation)。
字符集决定了数据库能够存储哪些字符,比如 ASCII 字符集只能存储简单的英文、数字和一些控制字符;GB2312 字符集可以存储中文;Unicode 字符集能够支持世界上的各种语言。
排序规则定义了字符集中字符的排序顺序,包括是否区分大小写,是否区分重音等。对于中文而言,排序方式与英文有所不同;中文通常需要按照拼音、偏旁部首或者笔画进行排序。
如果想要支持中文排序,最简单的方式就是使用支持中文排序的排序规则;但是常见的 Unicode 字符集默认不支持中文排序。所以我们需要解决这种情况下的中文排序问题。
首先是 Oracle,使用 AL32UTF8 字符编码时不支持中文排序规则,可以通过一个转换函数实现该功能。以下示例按照员工姓名的拼音进行排序:
-- Oracle 实现中文拼音排序
SELECT emp_name
FROM employee
WHERE dept_id = 4
ORDER BY NLSSORT(emp_name,'NLS_SORT = SCHINESE_PINYIN_M');
NLSSORT 是一个函数,返回了按照某种排序规则得到的字符序列;SCHINESEPINYINM 表示中文的拼音排序规则。该查询的结果如下:

Oracle 还支持按偏旁部首进行排序:SCHINESERADICALM,以及按笔画进行排序:SCHINESESTROKEM。
再来看一下 MySQL 的中文排序。MySQL 8.0 默认使用 utf8mb4 字符编码,不支持中文排序规则。以下语句按照员工姓名的拼音进行排序:
-- MySQL 实现中文拼音排序
SELECT emp_name
FROM employee
WHERE dept_id = 4
ORDER BY CONVERT(emp_name USING GBK);
CONVERT 是一个函数,用于转换数据的字符集编码;这里是中文 GBK 字符集,默认使用拼音排序。该语句的结果和上面的 Oracle 示例一样。
对于 SQL Server,字符集和排序规则是同一个概念。如果需要存储中文,需要使用相应的排序规则,例如 ChinesePRCCSAIWS。以下查询按照员工姓名的拼音进行排序:
-- SQL Server 实现中文拼音排序
SELECT emp_name
FROM employee
WHERE dept_id = 4
ORDER BY emp_name COLLATE Chinese_PRC_CI_AI_WS;
COLLATE 表示按照某种排序规则进行排序;如果数据库使用的是 ChinesePRCCIAIWS 排序规则,可以省略 COLLATE 选项。该语句的结果和上面的 Oracle 示例一样。
SQL Server 还支持按笔画进行排序:ChinesePRCStrokeCIAI_WS。
最后,PostgreSQL 默认使用 UTF8 编码字符集,不支持中文排序规则。以下示例按照员工姓名的拼音进行排序:
-- PostgreSQL 实现中文拼音排序
SELECT emp_name
FROM employee
WHERE dept_id = 4
ORDER BY emp_name COLLATE "zh_CN";
COLLATE 指定了中文排序规则 zh_CN,该语句的结果和上面的 Oracle 示例一样。
对于排序操作,还需要注意空值的排序问题。
SQL 空值排序
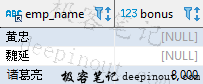
空值(NULL)在 SQL 中表示未知或者缺失的值。如果排序的字段中存在空值时,应该如何处理呢?以下语句按照奖金从低到高进行排序:
SELECT emp_name, bonus
FROM employee
WHERE dept_id = 2
ORDER by bonus;
在 MySQL 和 SQL Server 中空值排在了最前,查询的结果如下:

对于 Oracle 和 PostgreSQL 而言,也可以使用 NULLS FIRST 将空值排在最前,或者 NULLS LAST 将空值排在最后。以下语句返回的结果与 MySQL 和 SQL Server 一致:
-- Oracle 和 PostgreSQL 实现
SELECT emp_name, bonus
FROM employee
WHERE dept_id = 2
ORDER by bonus NULLS FIRST;
总而言之:
- MySQL 和 SQL Server 认为空值最小,升序时空值排在最前,降序时空值排在最后;
- Oracle 和 PostgreSQL 认为空值最大,升序时空值排在最后,降序时空值排在最前;同时支持使用 NULLS FIRST 和 NULLS LAST 指定空值的顺序。
解决空值的排序问题还有一个更通用的方法,就是利用 COALESCE 函数将空值转换为一个指定的值。例如,将奖金为空的数据转换为 0,这样升序排序时一定在最前:
SELECT emp_name, COALESCE(bonus, 0) AS bonus
FROM employee
WHERE dept_id = 2
ORDER BY COALESCE(bonus, 0);
该语句的执行结果如下:

COALESCE 函数用于将 bonus 为空的数据转换为 0。
SQL 排序常见问题
问题1描述
可以理解在WHERE条件字段上加索引,但是为什么在ORDER BY字段上还要加索引呢?这个时候已经通过WHERE条件过滤得到了数据,已经不需要再筛选过滤数据了,只需要根据字段排序就好了。
解答
在MySQL中,支持两种排序方式,分别是FileSort和Index排序。在Index排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。而FileSort排序则一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件I/O到磁盘进行排序的情况,效率较低。
所以使用ORDER BY子句时,应该尽量使用Index排序,避免使用FileSort排序。当然你可以使用explain来查看执行计划,看下优化器是否采用索引进行排序。
优化建议:
- SQL中,可以在WHERE子句和ORDER BY子句中使用索引,目的是在WHERE子句中避免全表扫描,在ORDER BY子句避免使用FileSort排序。当然,某些情况下全表扫描,或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。一般情况下,优化器会帮我们进行更好的选择,当然我们也需要建立合理的索引。
- 尽量使用Index完成ORDER BY排序。如果WHERE和ORDER BY后面是相同的列就使用单索引列;如果不同就使用联合索引。
- 无法使用Index时,需要对FileSort方式进行调优。
问题2描述
ORDER BY是对分的组排序还是对分组中的记录排序呢?
解答
ORDER BY就是对记录进行排序。如果你在ORDER BY前面用到了GROUP BY,实际上这是一种分组的聚合方式,已经把一组的数据聚合成为了一条记录,再进行排序的时候,相当于对分的组进行了排序。