我们在做统计的时候,可能需要先对数据按照不同的数值进行分组,然后对这些分好的组进行聚集统计。对数据进行分组,需要使用GROUP BY子句。
SQL GROUP BY 基本使用
比如我们想按照英雄的主要定位进行分组,并统计每组的英雄数量。
SELECT COUNT(*), role_main FROM heros GROUP BY role_main
运行结果(6条记录):

如果我们想要对英雄按照次要定位进行分组,并统计每组英雄的数量。
SELECT COUNT(*), role_assist FROM heros GROUP BY role_assist
运行结果:(6条记录)

你能看出如果字段为NULL,也会被列为一个分组。在这个查询统计中,次要定位为NULL,即只有一个主要定位的英雄是40个。
我们也可以使用多个字段进行分组,这就相当于把这些字段可能出现的所有的取值情况都进行分组。比如,我们想要按照英雄的主要定位、次要定位进行分组,查看这些英雄的数量,并按照这些分组的英雄数量从高到低进行排序。
SELECT COUNT(*) as num, role_main, role_assist FROM heros GROUP BY role_main, role_assist ORDER BY num DESC
运行结果:(19条记录)

SQL 数据分组
SQL 中的 GROUP BY 子句可以将数据按照某种规则进行分组。以下示例使用 GROUP BY 将员工按照性别进行分组:
SELECT sex
FROM employee
GROUP BY sex;
sex|
----|
男 |
女 |
GROUP BY 将性别的每个不同取值分为一组,每个组返回一条记录。由于员工表中只存在两种不同的性别,返回的结果只有两条记录。该语句与下面 DISTINCT 关键字的效果相同:
SELECT DISTINCT sex
FROM employee;
sex|
----|
男 |
女 |
DISTINCT 表示返回不重复的结果,也就是两种不同的性别。
SQL 多字段分组
GROUP BY 也可以基于多个字段或表达式进行分组。以下语句按照部门和性别的组合进行分组:
SELECT dept_id, sex
FROM employee
GROUP BY dept_id, sex;
dept_id| sex|
-------|----|
1|男 |
2|男 |
3|女 |
4|男 |
4|女 |
5|男 |
研发部(部门编号为 4)既有男性员工又有女性员工,因此分为 2 个组。
将 GROUP BY 子句与聚合函数一起使用可以实现数据的分组汇总功能。
SQL 分组汇总
分组汇总操作的示意图如下:

首先,基于分组字段的不同取值将数据分成 N 个组;然后在组内分别应用聚合函数进行统计,每个组返回一个分析结果。
我们来看一个示例。以下语句按照性别统计员工的数量和平均月薪:
SELECT sex, COUNT(*), AVG(salary)
FROM employee
GROUP BY sex;
sex| COUNT(*)|AVG(salary) |
---|---------|------------|
男 | 22|10145.454545|
女 | 3| 8200.000000|
先将员工按照性别分为两个组,然后使用聚合函数分别计算男女员工的总数和平均月薪。该查询的结果显示:男性员工有 22 人,平均月薪约为 10145;女性员工有 3 人,平均月薪为 8200。
SQL 多字段分组统计
我们再来看一个多字段分组统计的示例。以下语句按照部门和职位统计员工的数量和平均月薪,并且按照平均月薪从高到低进行排序:
SELECT dept_id, job_id, COUNT(*), AVG(salary)
FROM employee
GROUP BY dept_id, job_id
ORDER BY AVG(salary) DESC;
GROUP BY 按照部门和职位的不同组合进行分组,ORDER BY 按照统计后的平均月薪从高到低排序。该语句执行的结果如下:
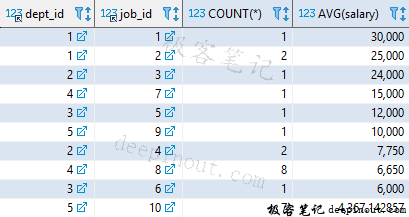
行政管理部中的总经理(职位编号为 1)的月薪最高(30000),人数最多(8 人)的是研发部的程序员(职位编号为 8)。
SQL 基于表达式分组统计
GROUP BY 也可以基于表达式的值进行分组统计。以下示例统计每年入职的员工数量:
-- Oracle、MySQL 以及 PostgreSQL 实现
SELECT EXTRACT(YEAR FROM hire_date) AS "入职年份",
COUNT(*) AS "员工数量"
FROM employee
GROUP BY EXTRACT(YEAR FROM hire_date)
ORDER BY EXTRACT(YEAR FROM hire_date);
-- SQL Server 实现
SELECT DATEPART(YEAR, hire_date) AS "入职年份",
COUNT(*) AS "员工数量"
FROM employee
GROUP BY DATEPART(YEAR, hire_date)
ORDER BY DATEPART(YEAR, hire_date);
EXTRACT 函数和 DATEPART 函数用于提取入职日期中的年份信息,我们在第 10 篇中学习了这两个函数。该语句执行的结果如下:
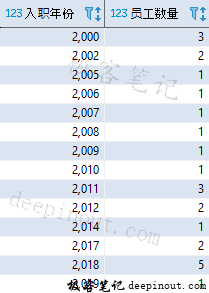
该查询的结果列出了从 2000 年到现在每年入职员工的数量分布。
SQL 空值分组
对于分组操作而言,同样需要注意空值问题。对于 GROUP BY,如果分组字段中存在多个 NULL 值,它们将被分为一个组。以下示例按照奖金统计员工的数量:
SELECT bonus, COUNT(*)
FROM employee
GROUP BY bonus;
bonus |COUNT(*)|
--------|--------|
10000.00| 3|
8000.00| 1|
[NULL]| 16|
5000.00| 2|
6000.00| 1|
2000.00| 1|
1500.00| 1|
从查询结果可以看出,16 个员工没有奖金;但是他们都被分组同一个组中,而不是多个不同的组。
SQL 分组后的过滤
我们知道 WHERE 条件可以用于过滤表中的数据。但是如果需要针对分组之后的结果进行过滤,是不是也可以使用 WHERE 实现呢?以下示例按照部门统计平均月薪,然后选择平均月薪大于 10000 的数据:
-- 使用 WHERE 执行分组后的过滤
SELECT dept_id, AVG(salary)
FROM employee
WHERE AVG(salary) > 10000
GROUP BY dept_id;
该语句在所有数据库中都返回了类似的错误信息:WHERE 子句中不允许使用聚合函数。因为 SQL 中的 WHERE 子句在 GROUP BY 子句之前执行,它是针对 FROM 中的表进行数据过滤;也就是说,WHERE 子句执行时还没有进行分组操作,没有计算 AVG(salary) 函数。
为了支持基于汇总结果的过滤,SQL 提供了 HAVING 子句;同时要求 HAVING 必须与 GROUP BY 一起使用。上面的错误示例可以修改如下:
SELECT dept_id, AVG(salary)
FROM employee
GROUP BY dept_id
HAVING AVG(salary) > 10000;
dept_id|AVG(salary) |
-------|------------|
1|26666.666667|
2|13166.666667|
HAVING 子句位于 GROUP BY 之后,对 AVG(salary) 函数的结果进行过滤。查询的结果显示只有 2 个部门的平均月薪大于 10000。
因此,在 SQL 语句中可以使用 WHERE 子句对表进行过滤,同时使用 HAVING 对分组结果进行过滤。例如,以下语句用于查询月薪大于 10000 的员工数量超过 2 人的部门:
SELECT dept_id, COUNT(*)
FROM employee
WHERE salary > 10000
GROUP BY dept_id
HAVING COUNT(*) > 2;
dept_id|COUNT(*)|
-------|--------|
1| 3|
首先,使用 WHERE 条件找出月薪大于 10000 的员工;然后 GROUP BY 按照部门统计员工的数量;最后使用 HAVING 子句选择数量大于 2 的部门。查询结果显示,行政管理部(dept_id = 1)有 3 名员工月薪超过了 10000。
从性能的角度来说,应该尽量使用 WHERE 条件过滤掉更多的数据,而不是等到分组之后再使用 HAVING 进行过滤;但如果业务需求只能基于汇总之后的结果进行过滤,那就另当别论了。
SQL 分组常见错误
在使用分组汇总时,初学者常见的一个错误就是在 SELECT 列表中使用了既不是聚合函数,也不属于分组字段的字段。例如:
-- GROUP BY 错误示例
SELECT dept_id, emp_name, AVG(salary)
FROM employee
GROUP BY dept_id;
以上语句会返回一个错误:字段 emp_name 没有出现在 GROUP BY 子句或者聚合函数中。原因在于该查询按照部门进行分组,但是每个部门包含多个员工;因此无法确定需要显示哪个员工的姓名。这是一个逻辑上的错误,而不是数据库实现的问题。
SQL 除了支持对数据进行分组汇总之外,还可以基于汇总数据进行再次过滤。